Oracle Big Data
Appliance:
a)
Importance
of Big Data:
Manufacturing
companies deploy sensors in their products to return a stream of telemetry.
Sometimes
this is used to deliver services like OnStar, that delivers communications,
security and navigation services. Perhaps more importantly, this telemetry also
reveals usage patterns, failure rates and other opportunities for product
improvement that can reduce development and assembly costs.
Retailers
usually know who buys their products.
Use of social media and web log files from their ecommerce sites can
help them understand who didn’t buy and why they chose not to, information not
available to them today. This can enable
much more effective micro customer segmentation and targeted marketing
campaigns, as well as improve supply chain efficiencies. Finally, social media
sites like Facebook and LinkedIn simply wouldn’t exist without big data. Their
business model requires a personalized experience on the web, which can only be
delivered by capturing and using all the available data about a user or member.
b)
Building a
Big Data Platform:
1) Acquire big
data: NoSQL databases are frequently used to acquire and store big data. They
are well suited for dynamic data structures and are highly scalable. The data
stored in a NoSQL database is typically of a high variety because the systems
are intended to simply capture all data without categorizing and parsing the
data. For example, NoSQL databases are
often used to collect and store social media data. While customer facing
applications frequently change, underlying storage structures are kept simple.
Instead of designing a schema with relationships between entities, these simple
structures often just contain a major key to identify the data point, and then
a content container holding the relevant data. This simple and dynamic
structure allows changes to take place without costly reorganizations at the
storage layer.
2) Organize big
data: Apache Hadoop is a new technology that allows large data volumes to be
organized and processed while keeping the data on the original data storage
cluster. Hadoop Distributed File System (HDFS) is the long-term storage system
for web logs for example. These web logs are turned into browsing behavior (sessions)
by running MapReduce programs on the cluster and 6 generating aggregated
results on the same cluster. These aggregated results are then loaded into a
Relational DBMS system.
3) Analyze big
data: Since data is not always moved during the organization phase, the
analysis may also be done in a distributed environment, where some data will
stay where it was originally stored and be transparently accessed from a data
warehouse. The infrastructure required for analyzing big data must be able to
support deeper analytics such as statistical analysis and data mining, on a
wider variety of data types stored in diverse systems; scale to extreme data
volumes; deliver faster response times driven by changes in behavior; and
automate decisions based on analytical models. Most importantly, the
infrastructure must be able to integrate analysis on the combination of big
data and traditional enterprise data. New insight comes not just from analyzing
new data, but from analyzing it within the context of the old to provide new
perspectives on old problems.
Oracle’s Big Data Appliance Solution:
Oracle
Big Data Appliance comes in a full rack configuration with 18 Sun servers for a
total storage capacity of 648TB. Every server in the rack has 2 CPUs, each with
6 cores for a total of 216 cores per full rack. Each server has 48GB1 memory
for a total of 864GB of memory per full rack.
Oracle Big Data Appliance Softwares:
The
Oracle Big Data Appliance integrated software includes:
è Full distribution of Cloudera’s Distribution
including Apache Hadoop (CDH)
è Cloudera
Manager to administer all aspects of Cloudera CDH
è Open source distribution of the statistical
package R for analysis of unfiltered data on Oracle Big Data Appliance
è Oracle NoSQL Database Community Edition3
è And Oracle Enterprise Linux operating system
and Oracle Java VM
a) Oracle Big Data Connectors: Oracle Big Data Connectors
enables an integrated data set for analyzing all data. Oracle Big Data
Connectors can be installed on Oracle Big Data Appliance or on a generic Hadoop
cluster.
b) Oracle Loader for Hadoop: Oracle Loader for Hadoop (OLH)
enables users to use Hadoop MapReduce processing to create optimized data sets
for efficient loading and analysis in Oracle Database 11g. Unlike other Hadoop
loaders, it generates Oracle internal formats to load data faster and use less
database system resources.
c) Oracle Direct Connector for Hadoop Distributed File System [HDFS]: Oracle Direct Connector for Hadoop Distributed
File System (HDFS) is a high speed connector for accessing data on HDFS
directly from Oracle Database. Oracle Direct Connector for HDFS gives users the
flexibility of querying data from HDFS at any time, as needed by their
application. It allows the creation of an external table in Oracle Database, enabling
direct SQL access on data stored in HDFS. The data stored in HDFS can then be
queried via SQL, joined with data stored in Oracle Database, or loaded into the
Oracle Database.
d) Oracle Data Integrator Application Adapter for Hadoop: Oracle
Data Integrator Application Adapter for Hadoop simplifies data integration from
Hadoop and an Oracle Database through Oracle Data Integrator’s easy to use
interface. Once the data is accessible
in the database, end users can use SQL and Oracle BI Enterprise Edition to
access data.
e) Oracle R Connector for Hadoop: Oracle R
Connector for Hadoop is an R package that provides transparent access to Hadoop
and to data stored in HDFS. R Connector for Hadoop provides users of the
open-source statistical environment R with the ability to analyze data stored
in HDFS, and to run R models at scale against large volumes of data leveraging
MapReduce processing – without requiring R users to learn yet another API or
language. End users can leverage over
3500 open source R packages to analyze data stored in HDFS, while
administrators do not need to learn R to schedule R MapReduce models in
production environments.
f)
Oracle NoSQL
Database: Oracle NoSQL Database is a distributed, highly scalable,
key-value database based on Oracle Berkeley DB. It delivers a general purpose,
enterprise class key value store adding an intelligent driver on top of
distributed Berkeley DB. This intelligent driver keeps track of the underlying
storage topology, shards the data and knows where data can be placed with the
lowest latency. Unlike competitive solutions, Oracle NoSQL Database is easy to
install, configure and manage, supports a broad set of workloads, and delivers
enterprise-class reliability backed by enterpriseclass Oracle support.
Maximizing
the Business Value of Big Data
Oracle Big Data Appliance: The Oracle Big Data Appliance is an
engineered system optimized for acquiring, organizing and loading unstructured
data into Oracle Database 11g. The Oracle Big Data Appliance includes an open
source distribution of Apache Hadoop, Oracle NoSQL Database, Oracle Data
Integrator with Application Adapter for Hadoop, Oracle Loader for Hadoop, an
open source distribution of R, Oracle Linux, and Oracle Java HotSpot Virtual Machine.
Oracle NoSQL Database: Oracle NoSQL Database Enterprise Edition is a
distributed, highly scalable, key-value database. Unlike competitive solutions,
Oracle NoSQL Database is easy to install, configure and manage, supports a
broad set of workloads, and delivers enterprise-class reliability backed by
enterprise-class Oracle support.
Oracle Data Integrator Application Adapter for Hadoop: The new Hadoop
adapter simplifies data
integration from Hadoop and an Oracle Database through Oracle Data Integrator’s easy
to use interface.
Oracle Loader for Hadoop: Oracle Loader for Hadoop enables customers to
use Hadoop MapReduce processing to create optimized data sets for efficient
loading and analysis in Oracle Database 11g. Unlike other Hadoop loaders, it
generates Oracle internal formats to load data faster and use less database
system resources.
Oracle R Enterprise: Oracle R Enterprise integrates the open-source statistical
environment R with Oracle Database 11g. Analysts and statisticians can run
existing R applications and use the R client directly against data stored in
Oracle Database 11g, vastly increasing scalability, performance and security.
The combination of Oracle Database 11g and R delivers an enterprise-ready
deeply-integrated environment for advanced analytics.
Oracle NoSQL Database, Oracle Data Integrator Application Adapter for
Hadoop, Oracle Loader for Hadoop, and Oracle R Enterprise will be available
both as standalone software products independent of the Oracle Big Data
Appliance.
Big Data Architecture:
Understanding a Big Data Implementation and its Components
The
Use Case in Business Terms
Rather
than inventing something from scratch I’ve looked at the keynote use case
describing Smart Mall.
The
idea behind this is often referred to as “multi-channel customer interaction”,
meaning as much as “how can I interact with customers that are in my brick and
mortar store via their phone”. Rather than having each customer pop out there
smart phone to go browse prices on the internet, I would like to drive their
behavior pro-actively.
The
goals of smart mall are straight forward of course:
·
Increase store traffic within the mall
·
Increase revenue per visit and per transaction
·
Reduce the non-buy percentage
What
do I need?
In
terms of technologies you would be looking at:
·
Smart Devices with location information tied to an individual
·
Data collection / decision points for real-time interactions and
analytics
·
Storage and Processing facilities for batch oriented analytics
In
terms of data sets you would want to have at least:
·
Customer profiles tied to an individual linked to their identifying
device (phone, loyalty card etc.)
·
A very fine grained customer segmentation
·
Tied to detailed buying behavior
·
Tied to elements like coupon usage, preferred products and other product
recommendation like data sets
High-Level
Components
A
picture speaks a thousand words, so the below is showing both the real-time
decision making infrastructure and the batch data processing and model
generation (analytics) infrastructure.
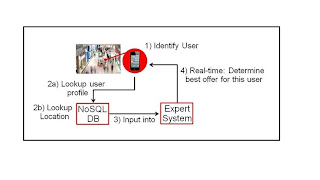
The
first – and arguably most important step and the most important piece of data –
is the identification of a customer. Step 1 is in this case the fact that a
user with cell phone walks into a mall. By doing so we trigger the lookups in
step 2a and 2b in a user profile database. We will discuss this a little more
later, but in general this is a database leveraging an indexed structure to do
fast and efficient lookups. Once we have found the actual customer, we feed the
profile of this customer into our real time expert engine – step 3. The models
in the expert system (customer built or COTS software) evaluate the offers and
the profile and determine what action to take (send a coupon for something).
All of this happens in real time… keeping in mind that websites do this in
milliseconds and our smart mall would probably be ok doing it in a second or
so.
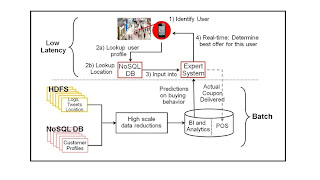
To
build accurate models – and this where a lot of the typical big data buzz words
come around, we add a batch oriented massive processing farm into the picture.
The lower half in the picture above shows how we leverage a set of components
to create a model of buying behavior. Traditionally we would leverage the
database (DW) for this. We still do, but we now leverage an infrastructure
before that to go after much more data and to continuously re-evaluate all that
data with new additions.
A word
on the sources. One key element is POS data (in the relational database) which
I want to link to customer information (either from my web store or from cell
phones or from loyalty cards). The NoSQL DB – Customer Profiles in the picture
show the web store element. It is very important to make sure this
multi-channel data is integrated (and de-duplicated but that is a different
topic) with my web browsing, purchasing, searching and social media data.
Once
that is done, I can puzzle together of the behavior of an individual. In
essence big data allows micro segmentation at the person level. In effect for
every one of my millions of customers!
The
final goal of all of this is to build a highly accurate model to place within
the real time decision engine. The goal of that model is directly linked to our
business goals mentioned earlier. In other words, how can I send you a coupon
while you are in the mall that gets you to the store and gets you to spend
money…
Detailed
Data Flows and Product Ideas
Now, how
do I implement this with real products and how does my data flow within this
ecosystem? That is something shown in the following sections…
Step 1 –
Collect Data
To
look up data, collect it and make decisions on it you will need to implement a
system that is distributed. As these devices essentially keep on sending data,
you need to be able to load the data (collect or acquire) without much delay.
That is done like below in the collection points. That is also the place to
evaluate for real time decisions. We will come back to the Collection points
later…
The
data from the collection points flows into the Hadoop cluster – in our case of
course a big data appliance. You would also feed other data into this. The
social feeds shown above would come from a data aggregator (typically a
company) that sorts out relevant hash tags for example. Then you use Flume or
Scribe to load the data into the Hadoop cluster.
Next
step is the add data and start collating, interpreting and understanding the
data in relation to each other.
For
instance, add user profiles to the social feeds and the location data to build
up a comprehensive understanding of an individual user and the patterns
associated with this user. Typically this is done using MapReduce on Hadoop.
The NoSQL user profiles are batch loaded from NoSQL DB via a Hadoop Input
Format and thus added to the MapReduce data sets.
To
combine it all with Point of Sales (POS) data, with our Siebel CRM data and all
sorts of other transactional data you would use Oracle Loader for Hadoop to
efficiently move reduced data into Oracle. Now you have a comprehensive view of
the data that your users can go after. Either via Exalytics or BI tools or, and
this is the interesting piece for this post – via things like data mining.
That
latter phase – here called analyze will create data mining models and
statistical models that are going to be used to produce the right coupons.
These models are the real crown jewels as they allow an organization to make
decisions in real time based on very accurate models. The models are going into
the Collection and Decision points to now act on real time data.
In the
picture above you see the gray model being utilized in the Expert Engine. That
model describes / predicts behavior of an individual customer and based on that
prediction we determine what action to undertake.
The
above is an end-to-end look at Big Data and real time decisions. Big Data
allows us to leverage tremendous data and processing resources to come to
accurate models. It also allows us to find out all sorts of things that we were
not expecting, creating more accurate models, but also creating new ideas, new
business etc.
Once
the Big Data Appliance is available you can implement the entire solution as
shown here on Oracle technology… now you just need to find a few people who
understand the programming models and create those crown jewels.
Software Architecture:
HDFS: Cloudera's
Distribution including Apache Hadoop (CDH) on Oracle Big Data Appliance uses
the Hadoop Distributed File System (HDFS). HDFS stores extremely large files
containing record-oriented data. It splits large data files into chunks of 64
MB, and replicates the chunk across three different nodes in the cluster. The
size of the chunks and the number of replications are configurable. Chunking
enables HDFS to store files that are larger than the physical storage of one
server. It also allows the data to be processed in parallel across multiple
machines with multiple processors, all working on data that is stored locally.
Replication assures the high availability of the data: if a server fails, the
other servers automatically take over its work load. HDFS is typically used to
store all the various types of big data.
Eg: Social
data from FB, twitter,
Oracle
NoSQL Database is a
distributed key-value database, built on the proven storage technology of
Berkeley DB Java Edition. Whereas HDFS stores unstructured data in very large
files, Oracle NoSQL Database indexes the data and supports transactions. But unlike
Oracle Database, which stores highly structured data, Oracle NoSQL Database has
relaxed consistency rules, no schema structure, and only modest support for
joins, particularly across storage nodes. NoSQL databases, or "Not Only
SQL" databases, have developed over the past decade specifically for
storing big data. However, they vary widely in implementation. Oracle NoSQL
Database has these characteristics:
■ Uses a system-defined, consistent hash index
for data distribution
■ Supports high availability through
replication
■ Provides single record, single operation
transactions with relaxed consistency guarantees
■ Provides a Java API
Oracle NoSQL
Database is designed to provide highly reliable, scalable, predictable, and
available data storage. The key-value pairs are stored in shards or partitions
(that is, subsets of data) based on a primary key. Data on each shard is
replicated across multiple storage nodes to ensure high availability. Oracle
NoSQL Database supports fast querying of the data, typically by key lookup. An
intelligent driver links the NoSQL database with client applications and
provides access to the requested key-value on the storage node with the lowest
latency.
Cloudera's
Distribution including Apache Hadoop (CDH) on Oracle Big Data Appliance
uses the Hadoop Distributed File System (HDFS). HDFS stores extremely large
files containing record-oriented data. It splits large data files into chunks
of 64 MB, and replicates the chunk across three different nodes in the cluster.
The size of the chunks and the number of replications are configurable.
Chunking enables HDFS to store files that are larger than the physical storage
of one server. It also allows the data to be processed in parallel across
multiple machines with multiple processors, all working on data that is stored
locally. Replication assures the high availability of the data: if a server
fails, the other servers automatically take over its work load.
Organizing Big Data: Oracle Big Data Appliance provides several
ways of organizing, transforming, and reducing big data for analysis:
■ MapReduce
■ Oracle R Support for Big Data
■ Oracle Big Data Connectors
MapReduce
The
MapReduce engine provides a platform for the massively parallel execution of
algorithms written in Java. MapReduce uses a parallel programming model for
processing data on a distributed system. It can process vast amounts of data
quickly and can scale linearly. It is particularly effective as a mechanism for
batch processing of unstructured and semi-structured data. MapReduce abstracts
lower level operations into computations over a set of keys and values.
Although big data is often described as unstructured, incoming data always has
some structure. However, it does not have a fixed, predefined structure when
written to HDFS. Instead, MapReduce creates the desired structure as it reads
the data for a particular job. The same data can have many different structures
imposed by different MapReduce jobs. A simplified description of a MapReduce
job is the successive alternation of two phases, the Map phase and the Reduce
phase. Each Map phase applies a transform function over each record in the
input data to produce a set of records expressed as key-value pairs. The output
from the Map phase is input to the Reduce phase. In the Reduce phase the Map
output records are sorted into key-value sets so that all records in a set have
the same key value. A reducer function is applied to all the records in a
set and a
set of output records are produced as key-value pairs. The Map phase is
logically run in parallel over each record while the Reduce phase is run in
parallel over all key values.
Oracle R Support for Big Data
R is an open
source language and environment for statistical analysis and graphing,
providing linear and nonlinear modeling, standard statistical methods,
time-series analysis, classification, clustering, and graphical data displays.
Thousands of open-source packages are available in the Comprehensive R Archive
Network (CRAN) for a spectrum of applications, such as bioinformatics, spatial
statistics, and financial and marketing analysis. The popularity of R has
increased as its functionality matured to rival that of costly proprietary
statistical packages. Analysts typically use R on a PC, which limits the amount
of data and the processing power available for analysis. Oracle eliminates this
restriction by extending the R platform to directly leverage Oracle Database
and Oracle Big Data Appliance for a fully scalable solution. Analysts continue
to work on their PCs using the familiar R user interface while manipulating
huge amounts of data stored in an Oracle database or in HDFS using massively
parallel processing.
For example,
an analyst might have a hypothesis about shopping behavior, which can be tested
using web logs. The analyst writes an R program on his or her PC and runs it on
a sample of data stored in Oracle Big Data Appliance. If the sample results are
promising, then the analyst can run the program on the entire web log and,
optionally, store the results in Oracle Database for further analysis. While
testing and developing the R program, the analyst works interactively and gets
the results
in real time. If the particular type of analysis warrants it, the program can
be scheduled to run overnight in batch mode as part of the routine maintenance
of the database.
The standard
R distribution is installed on all nodes of Oracle Big Data Appliance, enabling
R programs to run as MapReduce jobs on vast amounts of data. Users can transfer
existing R scripts and packages from their PCs to use on Oracle Big Data
Appliance. Oracle
R Connector for Hadoop provides R users high performance, native access to HDFS
and the MapReduce programming framework.
Oracle Big Data Connectors
Oracle Big
Data Connectors facilitate data access between data stored in CDH and Oracle
Database. They are licensed separately from Oracle Big Data Appliance.These are
the connectors
■ Oracle Direct Connector for Hadoop
Distributed File System
■ Oracle Loader for Hadoop
■ Oracle Data Integrator Application Adapter
for Hadoop
■ Oracle R Connector for Hadoop
Oracle Direct Connector for Hadoop Distributed File System
Oracle
Direct Connector for Hadoop Distributed File System (Oracle Direct Connector)
provides read access to HDFS from an Oracle database using external tables.
An external
table is an Oracle Database object that identifies the location of data outside
of the database. Oracle Database accesses the data by using the metadata
provided when the external table was created. By querying the external tables,
users can access data stored in HDFS as if that data were stored in tables in
the database. External tables are often used to stage data to be transformed
during a database load. These are a few ways that you can use Oracle Direct
Connector:
■ Access any
data stored in HDFS files
■ Access CSV
files generated by Oracle Loader for Hadoop
■ Load data
extracted and transformed by Oracle Data Integrator
Oracle Loader for Hadoop
Oracle
Loader for Hadoop is an efficient and high performance loader for fast movement
of data from CDH into a table in Oracle Database. Oracle Loader for Hadoop
partitions the data and transforms it into an Oracle-ready format on CDH. It
optionally sorts records by primary key before loading the data or creating
output files.
You can use
Oracle Loader for Hadoop as either a Java program or a command-line utility.
The load runs as a MapReduce job on the CDH cluster. Oracle Loader for Hadoop
also reads from and writes to Oracle Data Pump files.
Oracle Data Integrator Application Adapter for Hadoop
Oracle Data
Integrator (ODI) extracts, transforms, and loads data into Oracle Database from
a wide range of sources. In Oracle Data Integrator, a knowledge module (KM) is
a code template dedicated to a specific task in the data integration process.
You use ODI Studio to load, select, and configure the KMs for your particular
application. More than 150 KMs are available to help you acquire data from a
wide range of third-party databases and other data repositories. You only need
to load a few KMs for any particular job.
Oracle Data
Integrator Application Adapter for Hadoop contains the KMs specifically for use
with big data.
Oracle R Connector for Hadoop
Oracle R
Connector for Hadoop is an R package that provides an interface between the
local R environment, Oracle Database, and Hadoop on Oracle Big Data Appliance.
Using simple R functions, you can sample data in HDFS, copy data between Oracle
Database and HDFS, and schedule R programs to execute as MapReduce jobs. You
can return the results to Oracle Database or your laptop.
In-Database Analytics
Once data
has been loaded from Oracle Big Data Appliance into Oracle Database or Oracle
Exadata, end users can use one of the following easy-to-use tools for in-database,
advanced analytics:
Oracle R
Enterprise – Oracle’s version of the widely used Project R statistical
environment enables statisticians to use R on very large data sets without any
modifications to the end user experience. Examples of R usage include
predicting airline delays at a particular airports and the submission of
clinical trial analysis and results.
è In-Database
Data Mining – the ability to create complex models and deploy these on
very large data volumes to drive predictive analytics. End-users can leverage
the results of these predictive models in their BI tools without the need to
know how to build the models. For example, regression models can be used to
predict customer age based on purchasing behavior and demographic data.
è In-Database Text Mining – the
ability to mine text from micro blogs, CRM system comment fields and review
sites combining Oracle Text and Oracle Data Mining. An example of text mining
is sentiment analysis based on comments. Sentiment analysis tries to show how
customers feel about certain companies, products or activities.
è In-Database Semantic
Analysis – the ability to create graphs and connections between various
data points and data sets. Semantic analysis creates, for example, networks of
relationships determining the value of a customer’s circle of friends. When
looking at customer churn customer value is based on the value of his network,
rather than on just the value of the customer.
è In-Database Spatial – the
ability to add a spatial dimension to data and show data plotted on a map. This
ability enables end users to understand geospatial relationships and trends
much more efficiently. For example, spatial data can visualize a network of
people and their geographical proximity. Customers who are in close proximity
can readily influence each other’s purchasing behavior, an opportunity which
can be easily missed if spatial visualization is left out.
è In-Database MapReduce – the
ability to write procedural logic and seamlessly leverage Oracle Database
parallel execution. In-database MapReduce allows data scientists to create
high-performance routines with complex logic. In-database MapReduce can be
exposed via SQL. Examples of leveraging in-database MapReduce are
sessionization of weblogs or organization of Call Details Records (CDRs).






























